BFE的内网流量调度机制
背景
全局流量调度解决方案
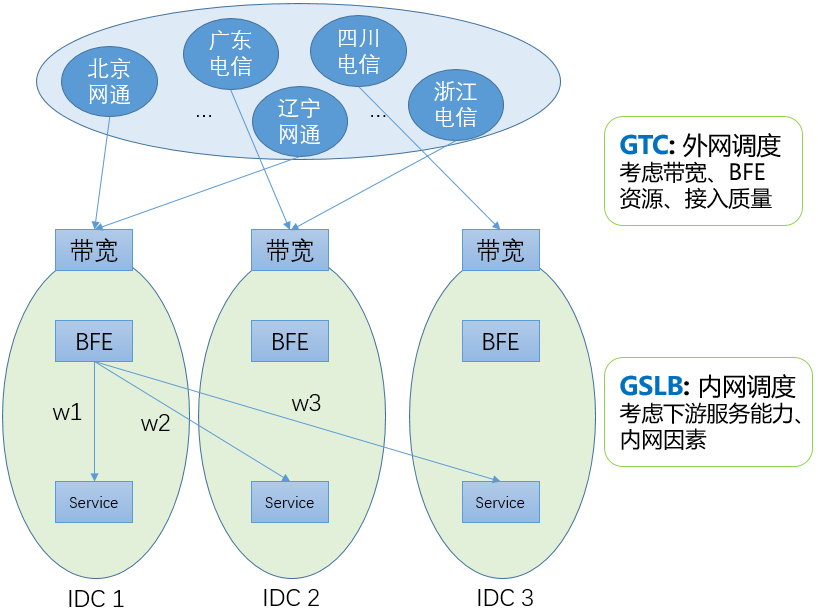
经过多年的建设,对于由IDC服务的业务流量,百度形成了两层的全局流量调度系统。包括:
-
GTC:外网流量调度
基于DNS生效,将各省、运营商的用户流量引导到合适的网络入口。在调度计算中,GTC要考虑外网带宽(容量和使用情况)、BFE平台的转发资源(容量和使用情况)、用户到各带宽出口的接入质量(连通性、访问延迟)等因素。
-
GSLB:内网流量调度
基于BFE生效,将到达各BFE集群的流量,按照权重转发到位于各数据中心的子集群。
外网流量调度
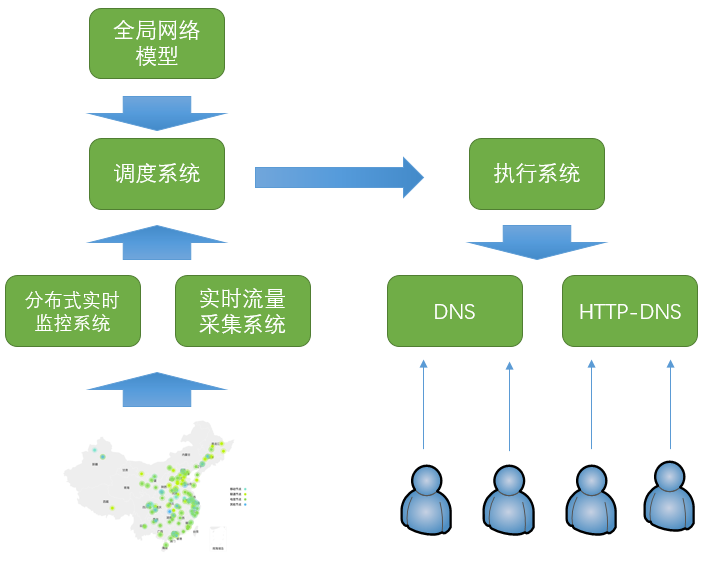
GTC负责在各网络入口间进行流量调度。GTC包括以下3个主要步骤:
-
实时监控
由位于各地的监控节点,持续向各外网接入点发送探测信号,对各地和接入点之间的连通性和质量进行监控。如果发现异常,分布式的实时监控系统会在1分钟内将故障信号上报给调度系统。
-
调度计算
实时流量采集系统从路由器获取实时的带宽使用情况,从七层负载系统获取实时的每秒请求情况。调度系统根据实时流量数据和实时监控情况,配合全局网络模型,在1分钟内计算出新的调度方案。
-
下发执行
调度系统将调度方案下发给DNS和HTTPDNS执行。由于DNS缓存的因素,客户端的生效需要一定的时间。百度大部分域名的DNS TTL设置为300秒(即5分钟)。一般在下发后,要经过8-10十分钟才能完成90%以上用户的生效。
和前一代外网调度系统相比,GTC有以下两方面的提升:
-
加快了外网故障处理的速度
通过“实时监控+自动调度计算”,从故障发生到启动DNS下发的时间压缩至2分钟以内。
-
降低了配置维护的成本
不需要针对域名维护复杂的预案。
业内很多类似的系统采用“预案”机制。例如,存在A和B两个备选的外网IP。预案会这么写:如果A出问题了,就把流量切换到B;如果B出问题了,就把流量切换到A。对于每个直接分配了IP地址的域名(也就是写为A记录的域名),都需要写这么一个预案。
预案机制的最大问题就是维护成本很高。首先,维护成本和外网出口的数量成指数关系。2个出口的情况是非常简单的;如果有5个甚至10个出口,预案是非常不好写的,需要考虑各种可能性。另外,维护成本和域名的数量成线性关系。如果有几千个域名,这时如果要对带宽出口做一个调整(增加、或删除一个出口),所要付出的工作量是惊人的。
外网流量调度主要适用于以下场景:
-
网络入口故障
由于网络入口本地、或运营商网络的故障,导致用户无法访问网络入口
-
网络入口由于攻击导致拥塞
大规模的DDoS攻击可以达到数百G,甚至达到T级别,可以直接将网络入口的入向带宽打满
-
网络接入系统故障
如四层负载均衡系统或七层负载均衡系统的故障
-
分省连通性故障
虽然从总体看网络入口可以访问,但是从某个运营商的某个地区无法访问。这部分是由于用户所在的地区出现网络局部异常,也可能是由于服务所使用的IP在局部地区被误封禁。
为什么需要内网流量调度
在多数据中心的场景下,如果没有内网流量调度机制,当一个数据中心内的服务发生故障时,只能通过改变域名对应的IP地址将流量调度到另外一个数据中心。如上文所说,在改变权威DNS的配置后,需要8-10分钟才能完成90%以上用户的生效。在完成切换之前,原来由故障IDC所服务的用户都无法使用服务。而且,运营商的Local DNS数量很大,可能会存在有故障或不遵循DNS TTL的Local DNS,从而导致对应的用户使用更长的时间完成切换,甚至一直都不切换。
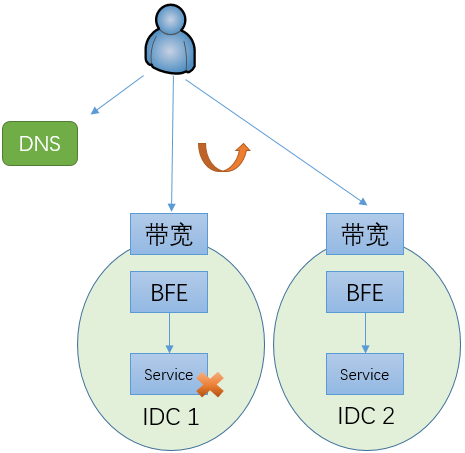
在引入内网流量调度机制后,可以通过修改BFE的配置将流量从故障的服务集群切走。在百度内部,配合自动的内网流量调度计算模块,在感知故障后,可以在30秒内完成流量的调度。和完全依赖外网流量调度的机制相比,故障止损时间有很大的降低,从8-10分钟降低至30秒内。而且,由于执行调度的BFE集群都在内部,内网流量调度的可控性也比基于DNS的外网流量调度要好的多。
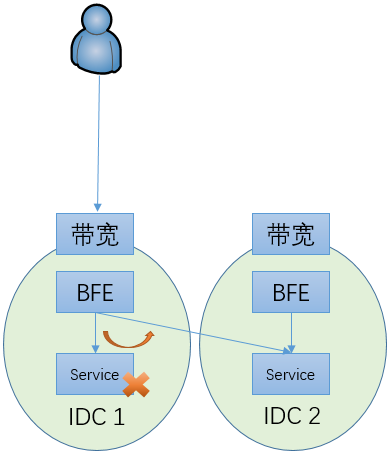
内网流量调度
基本工作机制
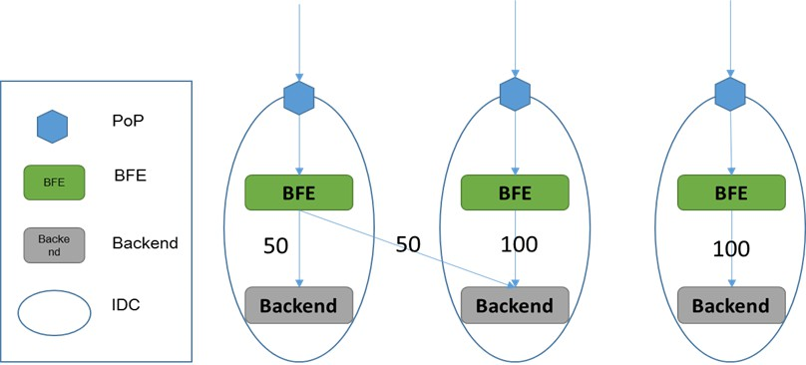
内网流量调度的工作机制如上图所示,其基本原理非常简单。在每个BFE集群,针对一个服务集群的每个后端子集群分配一组权重。在流量转发时,BFE按照这个权重来决定请求的目标子集群。
另外,对每个服务集群,还包含一个虚拟的子集群,称为BLACKHOLE(黑洞)。在黑洞集群对应的权重不为0的情况下,分给黑洞子集群的流量会被BFE主动丢弃。在到达BFE流量超过服务集群总体容量的情况下,可以通过启用黑洞集群用来防止服务集群的整体过载。
内网流量调度适用于和内部服务相关的场景,包括:
-
内部服务故障
在某些场景下(如:服务的灰度发布),可能单个服务子集群出现故障,从而导致服务容量下降、甚至完全无法提供服务。这时候可以通过内网流量调度快速完成止损处理。
-
内部服务压力不均
包括以下两种可能的场景:
-
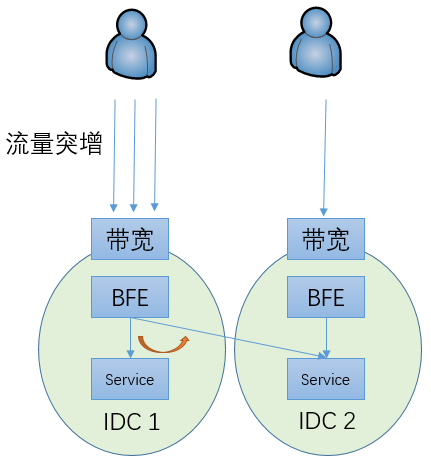
某个地区的用户流量突增,导致单个数据中心内的子集群服务压力超过容量
这时可以将部分流量调度到其它子集群来服务
-
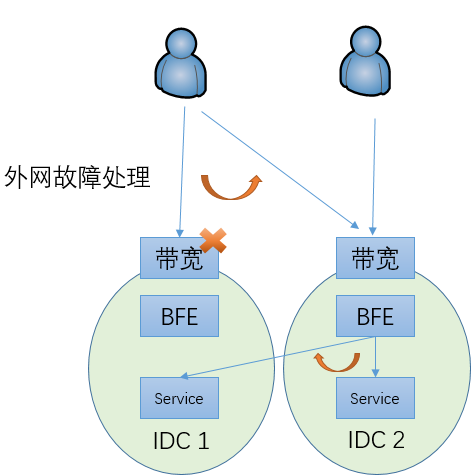
由于外网故障处理,在外网将部分流量从一个网络入口调度到另外一个网络入口,从而导致相关的子集群压力超过容量
这时也可以将部分流量调度到其它子集群来服务
-
内网自动流量调度
内网流量调度的权重可以手工设置。但实际上这个权重不应该是固定的,而应随着用户流量、服务集群的容量及机房间的连通性情况等因素的变化而调整。为此,在百度内实现了一个内网流量的调度器,用于对分流的权重比例进行计算。
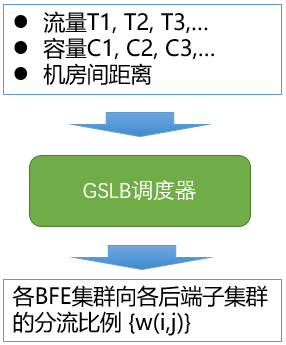
内网流量调度的总体机制为:
- 流量采集:基于BFE的访问日志,实时获取到达各BFE集群的各服务的流量
- 权重计算:根据流量、各服务子集群的容量、各数据中心网络连通性/距离等因素,计算各BFE集群向各服务子集群的分流权重
- 下发执行:由各BFE集群按照分流权重执行转发
目前在BFE开源项目中,支持内网流量调度权重的手工设置,未包含内网自动流量调度的相关模块。
示例场景
-
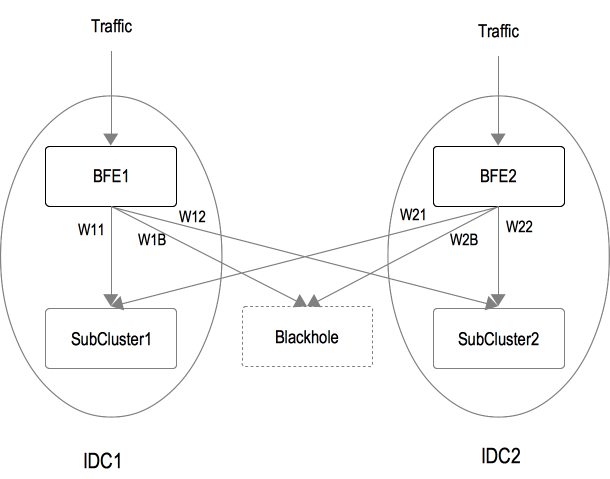
示例场景如下图所示,包含:
-
两个IDC:IDC_1和IDC_2
-
两个BFE集群:BFE_1和BFE_2
-
后端集群有两个子集群:SubCluster_1和SubCluster_2
-
-
可以针对BFE集群,设置子集群的分流比例,如:
-
BFE_1集群的分流配置为:{SubCluster_1: W11, SubCluster_2: W12, Blackhole: W1B}
-
BFE_2集群的分流配置为:{SubCluster_1: W21, SubCluster_2: W22, Blackhole: W2B}
-
-
BFE实例根据上述配置做WRR调度(加权轮询),向子集群转发请求
- 例如,当BFE_1的分流配置{W11, W12, W1B}为{45, 45, 10}时,BFE_1转发给SubCluster_1、SubCluster_2、Blackhole的流量比例依次为:45%、45%、10%。
-
通过修改上述配置,可以将流量在不同的子集群之间切换,实现负载均衡、快速止损、过载保护等目的。
内网转发的其它机制
失败重试机制
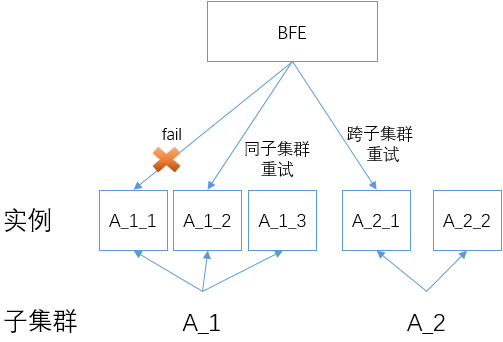
BFE在转发时,支持以下两种失败重试机制:
- 同子集群重试
- 在一次转发失败后,选择原目标子集群内的其它服务实例进行重试。
- 在同子集群内重试的最大次数,可以通过配置集群的参数“同子集群重试次数”来控制。
- 跨子集群重试
- 在转发失败后,在原目标子集群之外,使用另外一个子集群进行重试。
- 跨子集群重试的最大次数,可以通过配置集群的参数“跨子集群重试次数”来控制。
在转发失败后,BFE会首先尝试同子集群重试(如果同子集群重试次数大于1),然后再尝试跨子集群重试(如果跨子集群重试次数大于0)。
启用跨子集群重试功能要小心,在某些场景下这个功能可能将过量的流量转移到其它健康的集群,从而导致这些集群的压力过大、甚至被压垮。和上面“内网流量调度”中按照权重将流量转发到各子集群的机制不同,跨子集群重试所引发的流量压力是有一定不可控性的。
BFE并不是在所有请求失败的情况下都会进行重试。如果BFE感知到下游实例已经读取了请求(即使没有完整的读取),也不会再重试了。在这种情况下,BFE无法确认下游实例是否已经处理了请求,如果再次发送可能会导致状态的错误,所以采取了比较保守的策略。
连接池
BFE和下游实例的连接支持两种方式:
- 短连接方式:每次BFE向下游实例转发请求,均需要建立新的TCP连接
- 连接池方式:
- BFE为每个下游实例维护一个连接池。当BFE需要向某个下游实例转发请求时:
- 如果连接池中有idle连接,则复用这个连接
- 如果连接池中没有idle连接,则会建立一个新的TCP连接
- 当BFE处理完一个请求时
- 如果连接池中的idle连接数量小于连接池的大小,则将当前使用的连接放入连接池
- 如果连接池中的idle连接数量大于等于连接池的大小,则关闭当前使用的连接
- BFE为每个下游实例维护一个连接池。当BFE需要向某个下游实例转发请求时:
使用连接池的方式,可以避免新建TCP连接所导致的延迟,从而降低总的转发延迟。由于BFE需要对于每个下游实例都保持长连接,在某些情况下(如,BFE的实例数较大)可能导致下游实例的并发连接数较大。在使用连接池和设置连接池的参数时,需要结合以上因素综合考虑。
会话保持
BFE向下游转发请求时,支持将相同来源请求,转发至固定的业务后端(某个子集群或某个实例),这个功能被称为“会话保持”。
在执行会话保持时,BFE可以基于以下请求来源标识:
- 请求来源IP
- 请求特定头部,例如请求Cookie等
BFE支持以下两种会话保持级别:
- 子集群级别:相同来源的请求,被转发至固定的业务子集群(注:子集群中的任意实例)
- 实例级别:相同来源的请求,被转发至固定的业务实例