配置负载均衡算法及会话保持
配置负载均衡系统时,其中重要的参数就是如何设置负载均衡的算法。这决定了负载均衡系统如何将消息转发到后端的实例。
对BFE来说,一个后端集群可能包含多个子集群,子集群又可能包含多个实例。所以,负载均衡的算法在两层生效:子集群级别和实例级别。
子集群间的负载均衡
对于后端服务的一个集群,我们可以设置其所包含的子集群的权重。BFE会按子集群所设置权重,将请求的消息分配到子集群。
子集群间的负载均衡使用hash算法,再根据子集群的权重进行消息的按比例分配。缺省使用源IP进行hash计算。
配置示例
基于前面一章的例子,我们为后端服务的集群A进行扩容,增加一个子集群subCluster2,现在clusterA包含两个子集群subCluster1和subCluster2。由于两个子集群的处理能力不同,分别为其设置不同的流量比例。
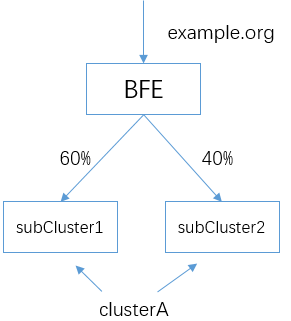
子集群的流量比例,可以在conf/cluster_conf/gslb.data中指定。
下面为该配置文件的内容。我们可以分别为两个子集群指定权重值,以支持上面的流量分配:
{
"Clusters": {
"clusterA": {
"GSLB_BLACKHOLE": 0,
"subCluster1": 60,
"subCluster2": 40,
}
}
}
子集群会话保持
对于子集群间的流量分配,BFE是根据请求消息中的字段(如IP地址、消息头等)进行hash计算,再按照配置的权重选择转发的后端。hash计算能保证携带相同信息的消息能被分配到相同的子集群,也就实现了子集群级别的会话保持。
当然,由于实现的方式是基于hash计算。所以,当子集群的数量有变化时,会对会话保持会受到一定影响,这个需要注意。
会话保持可以基于请求的源IP地址,或者请求的header中的特定域。具体使用哪种方式,可以通过配置文件来设置。
配置示例
在conf/server_data_conf/cluster_conf.data˙中,修改配置文件中的"HashConf"字段,设置子集群会话保持的属性。
如下实例中,BFE将会使用请求中名为UID的cookie进行hash计算。
Cookie: UID=12345
{
"config": {
...
"cluster_example": {
...
"GslbBasic": {
...
"HashConf": {
"HashStrategy": 0,
"HashHeader": "Cookie:UID",
"SessionSticky":false
}
}
}
}
参数具体含义
"HashConf"中字段的含义:
-
HashStrategy: 设置会话保持中使用的策略:
- 0:使用请求header中的域做会话保持,域的名字由"HashHeader"指定。
- 1: 使用请求的源IP地址做会话保持
- 2:优先使用header,如该header不存在,使用源IP。
-
HashHeader: 当使用header中的域进行会话保持时,该参数指定了header中域的名字。 比如在上面示例中,"Cookie:UID"指定使用名为UID的cookie做会话保持。
-
SessionSticky: 是否开启实例级别的会话保持。
实例间的负载均衡
一个子集群内部,我们可以定义多个实例。如何将这个子集群上的流量,分配到这些实例当中,这就涉及到实例间的负载均衡问题。
子集群的实例间的负载均衡算法支持:
- 平滑加权轮询
- 最少连接数
加权轮询的配置示例
加权轮询时是实例间负载均衡的缺省配置。使用这种方式,用户只需要设置实例的权重。
基于前面的子集群负载均衡的例子,我们为两个子集群中的实例设置不同的权重。支持如下的流量转发:
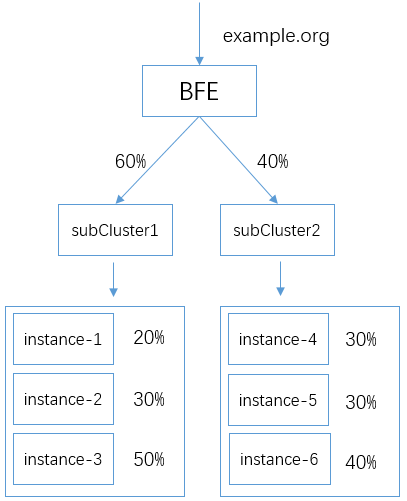
如前面所提到,实例的权重配置文件为 conf/cluster_conf/cluster_table.data
上述场景的配置如下:
{
"Config": {
"cluster_A": {
"subCluster1": [
{
"Addr": "192.168.2.1",
"Name": "instance-1",
"Port": 8080,
"Weight": 2
},
{
"Addr": "192.168.2.2",
"Name": "instance-2",
"Port": 8080,
"Weight": 3
},
{
"Addr": "192.168.2.3",
"Name": "instance-3",
"Port": 8080,
"Weight": 5
}
],
"subCluster2": [
{
"Addr": "192.168.3.1",
"Name": "instance-4",
"Port": 8080,
"Weight": 3
},
{
"Addr": "192.168.3.2",
"Name": "instance-5",
"Port": 8080,
"Weight": 3
},
{
"Addr": "192.168.3.3",
"Name": "instance-5",
"Port": 8080,
"Weight": 4
}
]
}
},
"Version": "1"
}
最小连接数配置的示例
如果需要在子集群的实例间使用最小连接数的负载均衡算法,修改conf/server_data_conf/cluster_conf.data中的 "BalanceMode"字段,如下:
{
"config": {
...
"cluster_example": {
...
"GslbBasic": {
...
"BalanceMode": "WLC",
...
}
}
}
修改上述配置项,后端请求会被转发到子集群中连接数最少的实例。
实例级别的会话保持示例
我们可以设置会话保持到后端实例。 修改配置,将conf/server_data_conf/cluster_conf.data中的"SessionSticky"变为true:
"GslbBasic": {
...
"HashConf": {
"HashStrategy": 0,
"HashHeader": "Cookie:UID",
"SessionSticky":true
}
当开启该功能,BFE会使用hash方式,计算得到子集群中的后端实例。这样,相同UID的消息,总能hash得到相同的后端,从而实现了会话保持功能。
这里也会出现同样的问题:如果后端实例列表发生变化,会话会转移到其他实例上。