负载均衡
租户的后端集群一般包含了多个子集群,每个后端子集群分别部署在不同地域不同机房中。每个子集群包含了一组处理能力差异化的后端实例。
业务通常采用多个后端子集群方式来管理后端服务, 可以带来如下好处:
- 多个子集群属于不同的故障隔离域,某个子集群出现故障(例如分级变更上线异常), 可以快速切换流量止损并提升整体可用性
- 多个子集群分布在离用户更近位置,可支持就近处理用户请求并优化访问体验
- 多个子集群同时服务提升整体容量,以满足高并发的互联网用户请求
相对应的,BFE的流量负载均衡包含了两个层级:
- 全局负载均衡(GSLB):BFE集群利用全量的用户流量、后端容量、网络情况,在多个后端子集群之间实现负载均衡。实现全局近实时决策优化,满足就近分发、调度止损、过载保护等目标。
- 分布式负载均衡(SLB):BFE实例分别独立的,将某个子集群的流量,在其多个后端实例之间实现负载均衡。实现细粒度实时负载均衡,满足实例均衡、异常实例屏蔽、重试容错等目标。
全局负载均衡
BFE在后端集群的多个子集群之间,采用基于WRR算法的负载均衡策略。 算法实现详见均衡模块 bfe_balance/bal_gslb/bal_gslb.go:subClusterBalance()。
全局负载均衡算法包括如下两个执行步骤:
步骤一、请求亲缘性及分桶处理
用户请求可能具有亲缘性,即需要常态将特定请求固定转发给某个子集群。例如:
- 来自某个用户的请求,常态固定转发给某个子集群处理,以便于用户分组管理
- 包含某个查询的请求,常态固定转发给某个子集群处理,以满足缓存友好性
为实现感知请求内容的负载均衡,BFE支持以下三种方式标识请求:
-
基于请求指定Header或Cookie
-
基于请求来源IP
-
优先基于请求指定Header或Cookie,缺失情况下基于请求IP
// bfe_balance/bal_gslb/bal_gslb.go
switch *bal.hashConf.HashStrategy {
case cluster_conf.ClientIdOnly:
hashKey = getHashKeyByHeader(req, *bal.hashConf.HashHeader)
case cluster_conf.ClientIpOnly:
hashKey = clientIP
case cluster_conf.ClientIdPreferred:
hashKey = getHashKeyByHeader(req, *bal.hashConf.HashHeader)
if hashKey == nil {
hashKey = clientIP
}
}
// if hashKey is empty, use random value
if len(hashKey) == 0 {
hashKey = make([]byte, 8)
binary.BigEndian.PutUint64(hashKey, rand.Uint64())
}
return hashKey
算法将用户的请求切分为100个桶,并基于指定策略(例如基于请求Cookie中的用户ID),将特定请求固定哈希到其中某个桶
// bfe_balance/bal_slb/bal_rr.go
func GetHash(value []byte, base uint) int {
var hash uint64
if value == nil {
hash = uint64(rand.Uint32())
} else {
hash = murmur3.Sum64(value)
}
return int(hash % uint64(base))
}
步骤二、请求桶分配及均衡
算法将100个桶,分配给权重和为100的所有子集群。
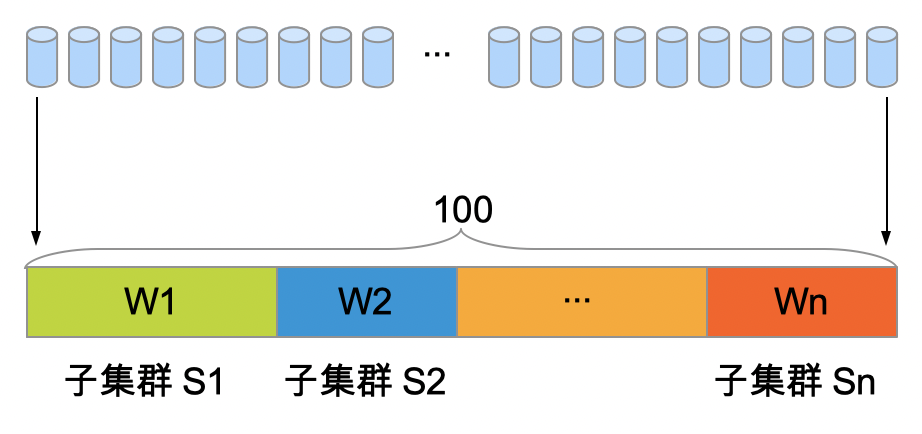
例如后端集群包含3个子集群S1/S2/S3,其权重分别为W1/W2/W3 且 W1+W2+W3=100, 则:
- 子集群S1分配到桶号范围为 [0, W1)
- 子集群S2分配到桶号范围为 [W1, W1+W2)
- 子集群S3分配到桶号范围为 [W1+W2,100)
// bfe_balance/bal_gslb/bal_gslb.go
// Calculate bucket number for incoming request
w = bal_slb.GetHash(value, uint(bal.totalWeight))
for i := 0; i < len(bal.subClusters); i++ {
subCluster = bal.subClusters[i]
// Find target subcluster for specified bucket
w -= subCluster.weight
if w < 0 {
return subCluster, nil
}
}
// Never come here
return nil, err.News("subcluster balancing failure")
分布式负载均衡
BFE在后端子集群的多个实例之间,支持多种负载均衡策略,包括:
- WRR: 加权轮训策略
- WLC: 加权最小连接数策略
算法实现详见 bfe_balance/bal_slb/bal_rr.go:Balance()。下文仅以WRR算法为例结合示例场景重点介绍。
步骤一、初始随机排序后端实例列表
BFE各转发实例在初始加载(或更新)后端子集群实例时,对实例列表预处理并随机排序。
// bfe_config/bfe_cluster_conf/cluster_table_conf/cluster_table_load.go
func (allClusterBackend AllClusterBackend) Shuffle() {
for _, clusterBackend := range allClusterBackend {
for _, backends := range clusterBackend {
backends.Shuffle()
}
}
}
这是为了避免在BFE转发实例较多情况下,由于各BFE转发实例产生相同的均衡结果,导致负载不均的情况。举例说明:假如上游的BFE集群规模是1000个实例,实际到达到用户请求是1000QPS,下游的后端子集群包含了10个后端实例,则可能周期性出现:
- 第一秒各BFE转发实例仅向第一个后端实例转发1000个请求
- 第二秒各BFE转发实例仅向第二个后端实例转发1000个请求
- 依次类推
BFE通过预先随机打乱后端子集群实例顺序,来避免以上负载不均的问题。
步骤二、平滑均衡选择后端实例
在后端实例权重差异较大情况下,也可能会出现负载不均的情况,表现为:虽然一个周期内各实例选中次数满足相应权重比例,但可能出现权重较大的实例连续多次被选择,而使得其它低权重的实例较长时间未分配流量。
为避免负载不均的情况,BFE使用了如下的WRR算法,简化的算法伪代码如下:
// bfe_balance/bal_slb/bal_rr.go
func smoothBalance(backs BackendList) (*backend.BfeBackend, error) {
var best *BackendRR
total, max := 0, 0
for _, backendRR := range backs {
backend := backendRR.backend
// select backend with greatest current weight
if best == nil || backendRR.current > max {
best = backendRR
max = backendRR.current
}
total += backendRR.current
// update current weight
backendRR.current += backendRR.weight
}
// update current weight for chosen backend
best.current -= total
return best.backend, nil
}
算法针对每个实例维护了两个参数:实例权重(Weight)、实例偏好指数(Current)。每次算法从所有可用后端列表中选出最佳后端的过程如下:
- 选择实例偏好指数最大的实例
- 更新各实例偏好指数:
- 对各实例的偏好指数值,分别加上该实例权重
- 对于选中实例,对其偏好指数值减去所有实例的偏好指数(在加上实例权重之前的值)总和
例如: 假设后端子集群包含三个后端实例a/b/c,权重分别为 5/1/1。如果基于以上算法,选择的过程如下:
| 轮数 | 选择前偏好指数 | 选中节点 | 选择后偏好指数 |
|---|---|---|---|
| 1 | 5 1 1 | a | 3 2 2 |
| 2 | 3 2 2 | a | 1 3 3 |
| 3 | 1 3 3 | b | 6 -3 4 |
| 4 | 6 -3 4 | a | 4 -2 5 |
| 5 | 4 -2 5 | c | 9 -1 -1 |
| 6 | 9 -1 -1 | a | 7 0 0 |
| 7 | 7 0 0 | a | 5 1 1 |